Algorithms
String Search
 Createhb21·2022년 01월 11일 20:28
Createhb21·2022년 01월 11일 20:28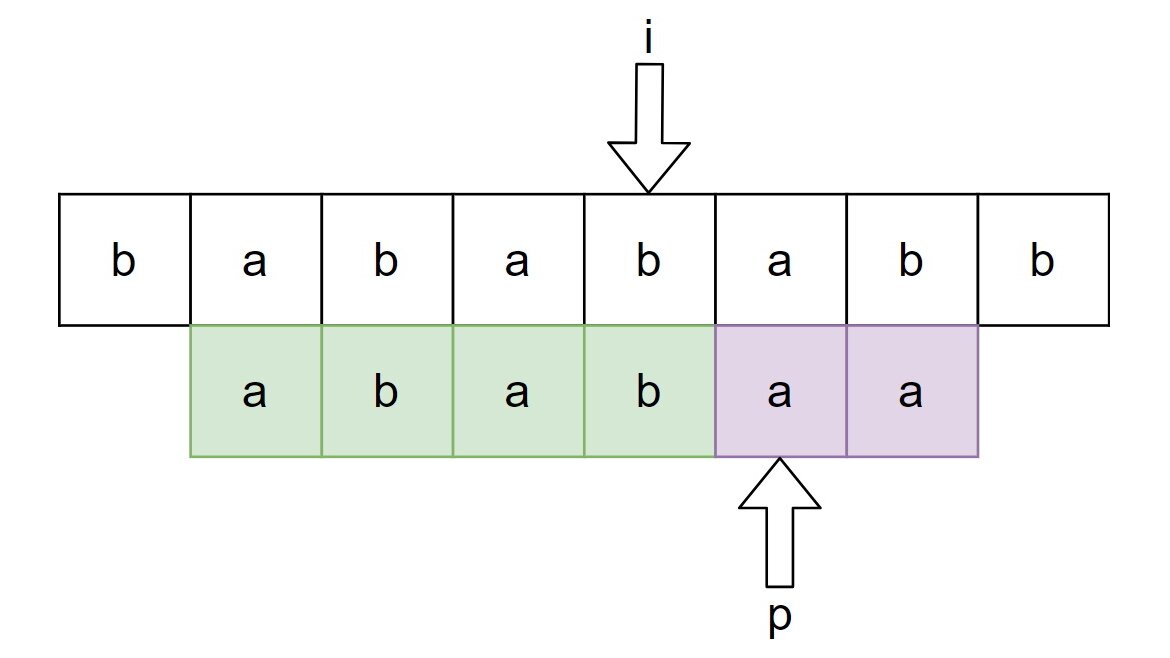
String Search Algorithms
긴 스트링에서 하위 스트링을 검색하는 알고리즘. 크게는 두 가지에 집중해볼 것인데, 하나는 순진한 방식의 스트링 탐색인데, 문제를 푸는데 가장 기본적이고 흔하게 사용되는 방법이다. 그리고 나면 조금 더 복잡하지만 더 나은 코딩 방법인 KMP 알고리즘을 살펴보자.
Naive String Search
긴 스트링에서 더 길이가 짧은 스트링이 몇 번 출현하는지를 세고 싶다고 하자. 가장 직관적인 방식은 글자의 조합을 각각 확인해 보는 것이다.
- 예시
"harold said haha in hamburg" 라는 스트링에 i의 인덱스를 찾는 다면 선형 탐색과 똑같은 방식으로 풀면 될 것이다. 하지만 만약 "haha" 와 같은 일정한 패턴을 확인해햐 한다면 어떻게 해야할까? 이는 더 이상 한 긃자 씩 확인하는 것이 아니므로 더 많은 작업이 필요하다. 혹은 다음과 같이 "wowomgzomg" 라는 스트링에 "omg" 는 몇번 출현하는지를 세야한다면 어떤 식으로 문제를 해결해야할까 ?

Pseudocode
// 해결 단계 1. stringSearch라는 함수를 정의하고, 함수는 긴 스트링 하나와 우리가 찾는 패턴 하나를 입력받는다. 2. 함수 내에서 최초의 긴 스트링에 루프를 건다. 3. 우리가 찾는 짧은 패턴의 스트링에도 루프를 건다. 4. 각 인덱스의 글자끼리 매치해보면서 글자가 일치하지 않으면 내부 루프를 멈춘다. 만약에 일치한다면 일치한 글자의 다음 인덱스의 글자를 매칭시켜본다. 5. 짧은 스트링이 끝날 때까지 반복한다. 짧은 스트링의 끝에 도달하면 일치하는 것을 하나 찾았다는 말이다. 6. 내부 루프를 완성해서 일치하는 것을 찾았다면 일치하는 개수(Count)를 하나 올려준다. 7. 마지막에 Count를 출력해준다.function naiveSearch(long, short) { let count = 0; for(let i = 0; i < long.length; i++){ for(let j = 0; j < short.length; j++) { if(short[j] !== long[i+j]) break; if(j === short.length - 1) count++; } } return count; } naiveSearch("lorie loled", "lol")
위와 같은 순진한 스트링 검색 구현 코딩 방식의 시간 복잡도는 텍스트의 길이를 N, 패턴의 길이를 M이라 할 때 각 텍스트의 인덱스에 대해 패턴이 일치하는지 비교하므로 O(NM)이다.
위의 방식보다 좀 더 빠르고 효율적으로 하는 방법은 없을까? 있다. KMP 문자열 검색 방식을 이용하면 O(N+M)에 문자열 검색을 할 수 있다.
KMP String Search
KMP 알고리즘은 문자열 매칭 알고리즘 중에서 가장 많이 활용이 되고 있는 알고리즘 중 하나다.
위와 같이 단순하게 모든 경우를 다 비교하는 경우는 최악의 경우 엄청난 시간이 소요될 수 있다. 예를 들어 길이가 10,000,000인 글에서 길이가 1,000인 부분 문자열을 찾으려는 경우 연산 양이 10,000,000,000이기 때문이다. 따라서 가급적 모든 경우를 다 비교하지 않아도 부분 문자열을 찾을 수 있는 KMP 알고리즘을 사용해야 한다.
KMP 알고리즘은 접두사와 접미사의 개념을 활용하여 '반복되는 연산을 얼마나 줄일 수 있는지'를 판별하여 매칭할 문자열을 파악하고 불필요한 문자열은 빠르게 점프하는 기법이다. 그래서 결과적으로 실패 함수라는 것을 구현을 할 것인데, 즉 매칭이 실패했을 때에 얼마나 점프를 할 수 있을지에 대한 정보를 접두사와 접미사라는 개념을 기준으로 알려주는 함수를 구현한다. 접두사와 접미사는 말 그래도 앞에 있는 문자열과 뒤에 있는 문자열을 의미한다. 예를 들어 abacaaba가 있을 때 다음과 같다.
접두사 접미사 a b a c a a b a
우리가 구해야 할 것은 위와 같이 접두사와 접미사가 일치하는 최대 길이이다. 위와 같이 접두사와 접미사를 구하게 되면 접두사와 접미사가 일치하는 경우에 한해서는 점프(Jump)를 할 수 있다는 점에서 몹시 효율적이다. 이제 위와 같은 접두사와 접미사의 최대 일치 길이는 어떻게 구할 수 있을지 알아보자.
KMP의 핵심 기법을 한 줄로 정리해보자면 "패턴을 정의해서, 했던 비교를 또 하지 않는다."라는 거다.
1. 패턴을 관리하는 failure 배열 만들기
KMP와 관련해서 기본적으로 2개의 문자열을 받는다.
검색의 대상이되는 문자열(origin)과, 찾아야하는 패턴의 문자(keyword).
그리고 여기에 KMP를 위해 추가되는 개념이 'failure funtion'다.
예를 들어보자.
전체 문자열 origin 은 전체 길이가 16인 'aabcacabcabcacab'이고
찾으려는 패턴 keyword은 길이가 10인 'abcabcacab'라고 했을때,
최종 failure function은 아래와 같은 배열의 형태를 띈다.

개념적으로는 failure function이라고하기 때문에 function인가? 싶을수도 있지만,
코드로 보자면 그냥 인덱스값을 가진 배열형의 변수다.
그리고 이 배열형의 변수 failure는, 찾고자 하는 문자열(keyword)이 반복하는 패턴을 기록해둔다.
즉 찾고자 하는 keyword가, 내부적으로 어떠한 '패턴'을 가지고 있다면
keyword를 찾기위해 전체 문자열인 origin과 0번 인덱스부터 비교해 나갈때,
서로 다르더라도 다시 처음부터 반복할 필요가 없게 만드는 것이다.
왜냐면 패턴만큼, 비교시의 인덱스를 건너뛰면되니까.
그럼 이제 failure라는 배열의 값들을 채우는 방법을 알아보자.
이를 채우는 개념은 아래와 같다.
1. 길이는 keyword와 동일
2. failure[0]의 값은 -1로 초기화한다.
3. 이후, 반복문을 통해 keyword배열을 순회하는데, 이때 중점은 현재 인덱스의 failure 값이 아니라,
한 칸 앞의 failure 인덱스의 값보다 +1한 keyword의 '값'을 봐야한다.
2. failure 배열을 활용해서 keyword 찾기
origin과 keyword를 첫 번째 인덱스부터 비교하기 시작할텐데,
여기서 달라지는 점은 바로, 비교하는 두 값이 다를 때 failure 배열을 활용한다는 것이다.
현재 origin 은 'aabcacabcabcacab'이고 찾으려는 패턴은 keyword 'abcabcacab'이다.
이제, 두 문자열의 첫 인덱스부터 비교를 시작하는데,

이와 같이, keyword와 origin이 달라졌을 경우에
우리가 이미 만들어놓은 failure 배열을 활용해주는 것이다.
keyword의 m번째 인덱스값 1에서 keyword와 origin의 값이 다르다.
현재 m의 값이 1이므로 한 칸 앞의 failure[0]번 값을 보자.
failure[0]번의 값은 -1이므로, 여기에 1을 더한 값 0이 m의 값이 된다.
즉, m은 다시 0이되고 n은 여전히 1인채로, 한 칸씩 비교를 계속 해나간다.

위의 방식처럼 반복적으로 한 칸씩 이동을 하게되면, 드디어 최종 패턴을 알 수 있게되고
위 예시를 기준으로 보자면 m이 9인 상태로 패턴을 찾아내게되며,
찾고자했던 origin 문자열에서의 keyword 문자열의 위치값은
최종 n 값에서 keyword의 길이값을 뺀 6이 된다.
Javascript KMP funciton
let kmp = function(origin, keyword){ let oDump = origin.split(''); let kDump = keyword.split(''); let oLength = origin.length; let kLength = keyword.length; let failure = []; failure.length = kDump.length; failure.fill(-1); // failure 배열 세팅 for(let i = 1; i < kLength; i++){ let idx = (1 + failure[i-1]); if(kDump[i] === kDump[idx]){ failure[i] = idx; } else{ failure[i] = -1 } } // 비교 시작 let n = 0, m = 0; while(m < kLength && n < oLength){ if(oDump[n] === kDump[m]){ n++; m++; } else if(m === 0){ n++; } else{ m = 1 + failure[m-1] } } return m === kLength? (n - kLength) : -1 }
Reference
- https://blinders.tistory.com/83
- https://www.udemy.com/
- https://www.youtube.com/watch?v=yWWbLrV4PZ8
# algorithms# search# string